이번 과제에서 집계 정보를 토대로 랭킹을 구현하는 목표가 존재했다.
요구사항은 다음과 같았다.
“상품의 일별 랭킹을 보여주세요.”
이러한 요구사항이 있을 때, 우리는 어떠한 생각을 가지고 나아가야 할까?
무엇을 기준으로 랭킹을 보여줘야할까?
우선 랭킹의 기준을 정의하는 것이 필요하다. 랭킹의 지표가 될 수 있는 것은 다양하다. 좋아요 수, 판매 수,조회 수가 존재했다. 그러면 이 지표들을 모두 합산하면 될까?
해당 지표들을 단순 합산하여 나타낼 경우 문제가 생길 수 있다.
만약 랭킹 지표가 **"좋아요 수 + 판매 수 + 조회 수”**라고 해보자. 그러면 판매와 조회가 같은 점수를 가지게 된다. 하지만 판매와 조회를 같은 선상에 두는 것은 실제 가치가 다르기 때문에 같이 봐선 안된다. 그래서 다음과 같이 가중치를 적용하였다.
Weighted Sum = 0.1 * viewCount + 0.2 * likeCount + 0.7 * salesCount
이를 통해 조회/좋아요/구매를 각각의 가중치를 가지고, 랭킹 점수에 반영하도록 하였다.
이때 상품 가격에 대해 차별을 둬야할 수도 있다. 500원 짜리 상품과 50만원 짜리 상품의 구매 가치는 다르다. 이럴 경우 구매 가중치 계산에 가격을 포함하여 계산할 수 있다. ex) Math.log10(price*amount + 1);
그럼 랭킹 데이터를 어떻게 보여줄까?
위에서 랭킹 점수를 어떻게 산정할 것인지 정의하였다. 그렇다면 각 상품의 랭킹 점수를 가지고 어떻게 순위를 보여줘야할까?
가장 단순한 구조를 가정하면, 아래와 같이 DB 쿼리를 이용할 수 있다.
SELECT
p.product_id,
p.view_count,
p.like_count,
p.sales_count,
(0.1 * p.view_count + 0.2 * p.like_count + 0.7 * p.sales_count) AS weighted_score
FROM product p
ORDER BY weighted_score DESC;데이터가 소규모라면 위 방식으로 충분한 해결 방안이 될 수 있다. 하지만 결국 모든 상품에 대하여 이 쿼리로 조회된다면, 상품이 많아질수록 느려지게 되고, 이는 DB 과부하로 이어질 수 있다. 따라서 다른 방법을 찾아야 한다.
Redis ZSet
Redis에는 ZSet 자료구조가 존재한다. ZSet은 Sorted Set으로, 고유한 문자열(멤버)로 구성된 컬렉션이며, 각 멤버는 점수(score)와 함께 저장된다.
ZSet은 Skip List + HashTable 형태로 되어있다. 하나의 예시로 80의 랭킹을 찾는 과정을 확인해보자.
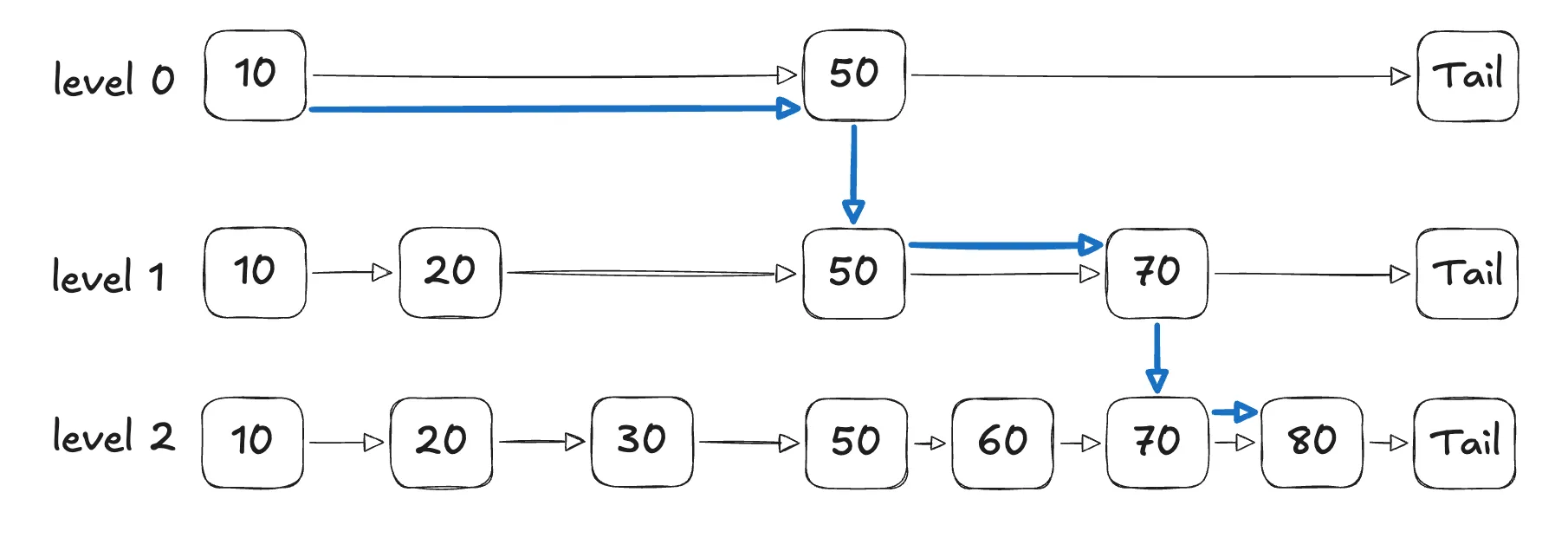
위 이미지를 보면 특정 member의 랭킹을 조회하는 데에 O(logN)이 소요되는 것을 알 수 있다. 특정 member 사입과 조회에는 O(logN)이 소요되고, TOP N개 조회 시에는 O(N)이 소요된다.
이 자료구조를 랭킹에 활용하여, member는 상품 ID로 하고, score는 상품의 랭킹 점수로 적용하면 비교적 쉽게 문제를 해결할 수 있다.
ZSet을 활용한 랭킹 보여주기
ZSet을 이용하여 다음 명령어를 통해 Redis에 score를 반영할 수 있다.
ZINCRBY ranking:all:20250911 0.8 // 좋아요 4개 증가에 따른 점수 반영
ZREVRANGE ranking:all:20250911 0 9 WITHSCORES // 탑 10 조회
현 시스템에서는 좋아요/조회/구매 시, 이벤트를 발행하고 이를 배치 리스너를 통해서 집계 데이터를 반영한다.
이후 랭킹 조회 API에서는 탑 N을 조회하여 상품 ID를 조회한다. 얻은 상품 ID를 통해 상품 정보를 조합하여 응답으로 보내준다. 이를 통해 DB를 통한 조회보다 비교적 간단하고 효율적으로 랭킹 기능을 제공할 수 있다.
날짜가 넘어가는 순간의 랭킹
요구사항을 보면 일별로 랭킹이 존재한다. 그리고 랭킹의 키는 “ranking:all:{date}”형식으로 되어 있다. 여기서 주의할 점은 날짜가 넘어갈 때이다.
날짜가 넘어가는 시점에 어떠한 처리도 하지 않는다면, 다음 날 모든 상품의 score가 0에서 시작한다.
물론 “다음 날 모든게 초기화되어야하는거 아니야?”라고 생각할 수 있지만, 넘어가는 시간에 데이터가 완전 바뀌게 되므로 사용자 입장에서 혼동이 올 수도 있고, 이를 악용한 사례가 발생할 수 있다. 이러한 상황을 Cold Start라 한다.
이러한 문제를 해결하기 위해, 23시 50분마다 당일의 score를 다음 날 score에 반영한다. 이때 score를 그대로 반영하지 않고, 10%만 반영해주었다.
그대로 반영하게 될 경우, 일별 랭킹의 의미가 퇴색될 수 있다. 마치 롱테일 현상처럼 누적되는 것과 같으므로, 전날의 score는 10%만 반영하여 위 문제를 해결하였다.
마무리
이번에 Redis의 ZSet을 활용하여 랭킹 기능을 구현해볼 수 있었다. 일간 랭킹의 경우, 비교적 손쉽게 적용할 수 있다. 또한 랭킹을 구현하는 과정에서 랭킹의 가중치와 Cold Start 문제에 대해 고민해보면서, 랭킹에서 생길 수 있는 문제들에 대해 생각이 넓어짐을 느낄 수 있었다.
하지만 일간 랭킹에서 더 나아가, 시간 별 랭킹, 실시간 랭킹 기능이 요구된다면 어떨까?
키를 그만큼 늘리면 되지 않을까 싶지만, 그만큼 키의 개수가 상당히 많아지게 된다. 가령 10분을 예시로 들면, 기존에 비해 하루 기준, 6 * 24 개의 키가 추가로 더 생성된다. 그리고 그 안에 (상품 ID, 랭킹 점수)를 가지므로 차지하는 메모리는 상당히 많아진다.
이럴 때 어떻게 관리하는게 좋을지 더 고민할 필요가 있을 것 같다.