카프카는 파티션 단위로 순서가 보장된다.
그런데 만약 파티션 내에서 순서보장이 필요없는 작업이라면 어떻게 해야할까?
예를 들어, 단순히 이벤트에 대해 감사 로그를 저장해야 하는 상황을 생각해보자. 그리고 순서를 보장할 필요가 없다고 가정하자.
이 작업에서 순서대로 저장되는 것이 중요할까?
순서 보장이 중요한 작업은 아닐 것이다. 또한 이벤트 생성시간을 함께 저장한다면, 충분할 수 있다.
이때 감사 로그를 저장하는 것을 병렬 처리로 수행하고싶은 생각이 들 수 있다.
이때 어떻게 병렬 처리를 수행할 수 있을까?
Parallel Consumer
이에 대한 대안으로 Confluent가 제공하는 카프카 오픈소스인 Parallel Consumer가 존재한다.
물론 파티션을 늘리고 Consumer를 더 붙여서 병렬로 처리할 수도 있다. 하지만 파티션을 무작정 증가시킬 수는 없다.
- 브로커 리소스 증가
- 리밸런싱 오버헤드
- 파티션은 다시 줄일 수 없음
이러한 단점이 있기 때문에, 파티션을 늘리는 것은 조심해야 한다. 이러한 상황에서 Parallel Consumer를 사용할 수 있다.
Parallel Consumer는 파티션 내에서 병렬 처리를 제공한다. 여러 컨슈머 스레드를 통해 파티션을 늘리지 않고 처리량을 늘릴 수 있다.
concurrency 옵션과 헷갈릴 수 있는데, concurrency는 컨슈머가 여러 파티션을 처리할 수 있게 하는 옵션이다. 즉, 파티션에 붙는 컨슈머를 어플리케이션이 아니라 스레드로 처리하는 것과 같다.
Parallel Consumer는 3가지 순서 보장 방식을 제공한다.
- Partition: 파티션 단위의 순서 보장
- Key: 키 단위의 순서 보장
- Unordered: 순서 보장 X
파티션 단위의 순서 보장은 기존 컨슈머와 방식이 같으므로 차이가 없다. 따라서 Key 방식과 Unordered 방식을 사용했을 때 큰 이점을 볼 수 있다.
Parallel Consumer에 대한 자세한 설명은 아래 네이버 D2 블로그에 나와있다.
https://d2.naver.com/helloworld/7181840
기존 Consumer와 어떻게 다르게 동작하는가?
보통 스프링 카프카를 사용한다면, 다음과 같이 코드를 작성한다.
@KafkaListener(topics "order-events", groupId = "order-consumer")
public void consume(ConsumerRecord<Object, Object> record, Acknowledgement ack) {
process();
ack.acknowledge();
}
이는 KafkaListenerContainer가 KafkaConsumer.poll()을 주기적으로 실행하고, poll로 가져온 레코드를 리스너 메서드에 전달하는 방식이다.
Parallel Consumer는 다음과 같이 작성하게 된다.
@Bean
public ParallelStreamProcessor<Object, Object> parallelConsumer(~) {
var options = ParallelConsumerOptions.<Object, Object>builder()
.ordering(ProcessingOrder.UNORDERED)
.consumer(auditKafkaConsumer)
.maxConcurrency(10)
.build();
ParallelStreamProcessor<Object, Object> pc =
ParallelConsumer.createEosStreamProcessor(options);
pc.subscribe(List.of("order-events"));
pc.poll(record -> {
process();
});
}
이는 내부적으로 KafkaConsumer.poll을 사용한다. 하지만 가져온 레코드를 Thread Pool에 분산시킨다.
이때 그러면 오프셋 커밋이 위험해질 수 있다.
Parallel Consumer - 여러 메세지 중 일부를 실패했을 때
Parallel Consumer가 여러 오프셋을 처리하다가 일부를 실패했다고 가정해보자.
- 1, 2, 3, 4, 5 오프셋 처리 시도
- 1, 3, 4, 5 처리 성공 / 2 처리 실패
이 경우 1번 오프셋까지 커밋하게 된다. 이에 따라 3, 4, 5는 중복하여 재시도할 것 같지만, 재시도 하지 않는다.
이는 Parallel Consumer가 오프셋 메타데이터를 관리하는데, 3, 4, 5는 완료한 오프셋으로 기록해놓기 때문이다.
즉, 처리하지못한 오프셋 저장소에는 2번만 있으므로, 3, 4, 5는 건너뛰고 2번 오프셋에 대해서만 처리한다.
Parallel Consumer - 내부 동작
전체적인 과정을 그림을 통해 확인해보자.
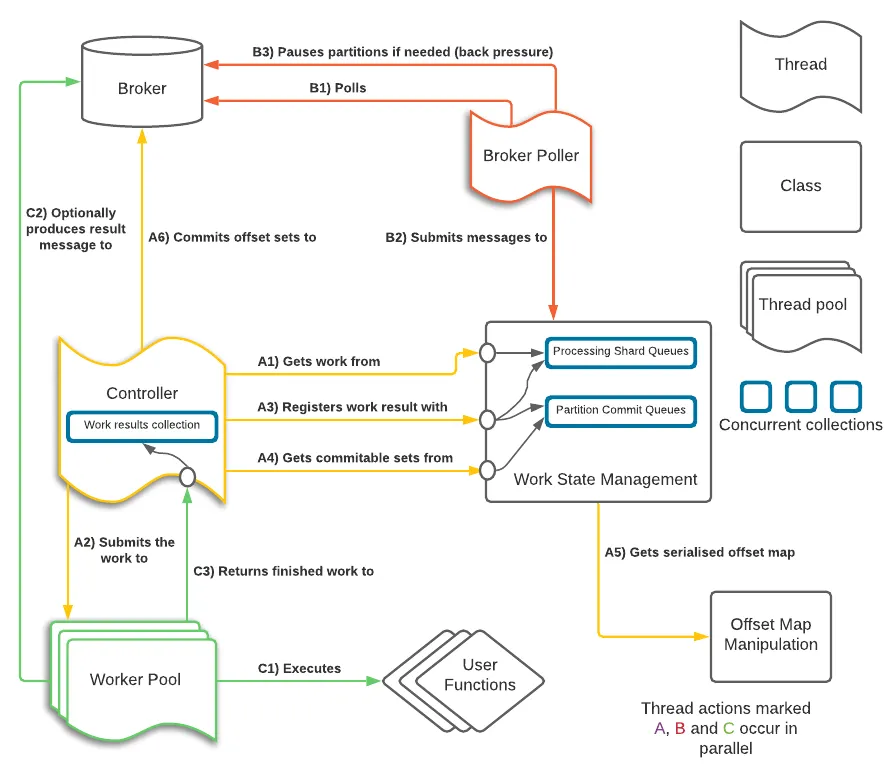
위 이미지에서 Controller와 Worker Pool을 봐보자.
Controller는 Worker Pool에 작업을 요청하고 완료한 작업 결과를 받는다. 그리고 이를 Work State Management에 기록한다. Work State Management 내에 오프셋 별 작업 완료 여부와 커밋할 오프셋을 따로 관리한다.
그리고 주기적으로 오프셋을 커밋하게 된다.
이러한 처리를 위해 enable.auto.commit: false로 필수로 지정해야 한다.
마무리
단순히 로그 저장하는 Consumer에서 “순서가 보장될 필요가 없는데, 멀티 스레드로 돌릴 수 없을까?”고민하다가 Parallel Consumer에 대해서 알게 되었다.
Parallel Consumer를 통해서 Key 또는 Unordered 단위의 순서 보장만 필요하다면, 좋은 선택지가 될 수 있다.
하지만, 기존 스프링 카프카를 사용하는 것보다 그만큼 관리 비용이 증가한다. 예를 들면, 스프링 카프카에서 DefaultErrorHandler를 사용했으면 이를 Parallel Consumer에서는 수동으로 처리해야 한다.
파티션을 늘리기 버거운 상황이고, 순서 보장이 Key 단위나 보장될 필요가 없다면, Parallel Consumer를 고려해봐도 좋을 것 같다.