우리는 문제 상황에 대응하기 위하여 다양한 도구를 사용한다. 이때 Circuit Breaker, Retry 등이 사용될 수 있다.
서킷 브레이커(circuit breaker)는 회로 차단기이다. 차단기는 문제 상황 시 회로를 차단하고, 어느정도 시간이 지난 뒤 기능이 동작하도록 복귀한다.
리트라이 (Retry)는 일시적인 장애 상황에서 재시도를 통해 정상 응답을 받아내기 위해 사용한다.
이때 위 두 개를 조합하여, 일시적인 장애 상황일 수 있으므로 재시도를 요청하고, 재시도 마저도 실패할 경우 해당 기능 실패로 분류할 수 있을 것이다.
- 일시적인 장애 상황일 수 있으므로, 재시도를 수행한다.
- 재시도마저도 실패한 경우, 진짜 실패가 된다.
Circuit Breaker와 Retry를 함께 사용
위와 같은 대처 상황을 만들고자할 때, 우리는 Circuit Breaker와 Retry를 자연스럽게 다음과 같이 적용할 것이다.
@Retry(name = "pgRequest")
@CircuitBreaker(name = "pgRequest", fallbackMethod = "requestFallback")
public GatewayResponse.Request request(Payment payment) {
ApiResponse<LoopersResponse> request = loopersRequestV1Client.request(~);
return GatewayResponse.Request.success(request.data().transactionKey());
}
public GatewayResponse.Request requestFallback(Payment payment, Throwable throwable) {
log.error("PG 결제 요청이 실패하였습니다. {}", throwable.getMessage());
return GatewayResponse.Request.fail();
}위의 Context를 바탕으로 코드를 보았을 때, “Retry하고, Retry마저 실패할 경우, fallback을 수행하겠지”라고 느껴진다.
하지만 이는 우리의 의도와 다를 수 있다. 이유가 무엇일까?
내가 보는 관점이 모두와 같지 않다.
나의 의도는 Retry → Circuit Breaker 순서로 작동할 것이라 생각했다. 그런데 사실 Resilience4j를 쓰는 모두가 나와 같은 의도를 가지지 않는다. 다른 누군가는 Circuit Breaker가 우선적으로 동작하길 원할 수 있다.
실제로 별다른 설정이 없는 상황에서 위 코드에서는 Circuit Breaker가 우선적으로 동작한다. 사실 위 코드는 아래와 같이 동작한다.
- 실패할 경우, Circuit Breaker가 먼저 동작 → fallback 처리
- Retry 입장에서는 실패가 아님 → 재시도하지 않음
@Test
@DisplayName("실패 후 재시도 요청도 실패하면, 서킷 브레이커 폴백 메서드를 호출한다.")
void fallback_whenRetryFails() {
given(loopersRequestV1Client.requestPayment(any())
.willThrow(FeignException.class);
// Circuit Breaker 수행으로 인한 fallback 확인 -> 성공
verify(loopersPaymentGateway, times(1)).requestFallback(any(), any());
// Retry 수행 여부 확인 -> 실패
verify(loopersRequestV1Client, times(2)).requestPayment(any());
}위 테스트 코드는 실패한다.
왜냐하면, Circuit Breaker가 먼저 수행되어 fallback 처리를 하기 때문이다. 그래서 Retry 입장에서는 실패라고 여기지 못하고, 재시도를 하지 않는다.
그렇다면, resilience4j의 실행 순서는?
Resilience4j의 순서는 다음과 같이 나타나있다.
As of release 0.16.0 as we set an implicit spring aspect order now which is retry then circuit breaker then rate limiter then bulkhead
위 글을 보았을 때, “Retry → Circuit Breaker → Rate Limiter → Bulkhead” 순으로 동작할 것이라 오해할 수 있다. GPT에게 해석해달라고 했을 때도, Retry → Circuit Breaker 순으로 동작한다고 알려준다. 하지만 실제 테스트를 실행해보면 Circuit Breaker가 먼저 수행된다.
아래 그림을 통해 알아보자.
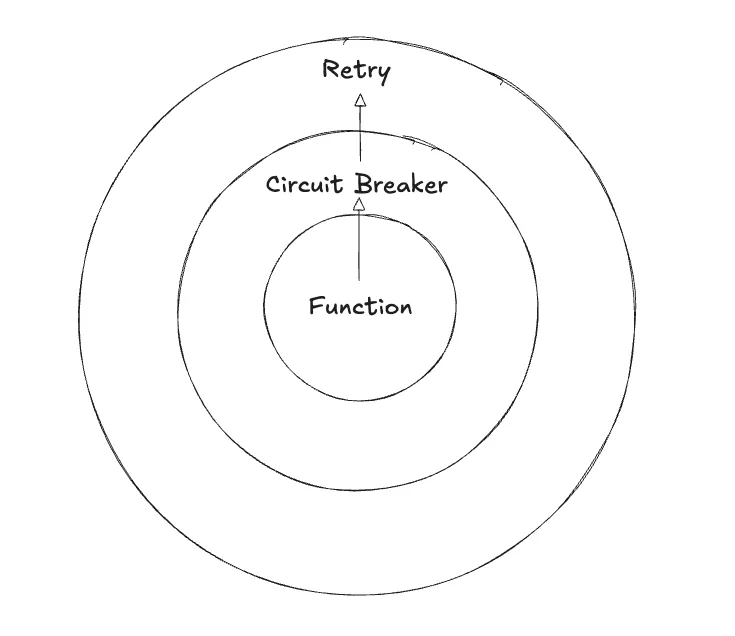
밖에서 안으로 들어오는 것이 아닌, 위 그림처럼 Function에서부터 밖으로 차례대로 수행된다고 이해해야 한다.
Retry ←( CircuitBreaker ← ( RateLimiter ← ( TimeLimiter ← ( Bulkhead ←( Function ) ) ) ) )
“retry then circuit breaker then rate limiter then bulkhead”라는 문장이 Function 다음 retry → circuit breaker → Rate Limiter이 수행되는 것처럼 느껴지지만, 그림의 방향처럼 안쪽에서부터 바깥 방향으로 적용된다고 생각해야 한다.
순서를 Custom 하는 방법
순서를 Custom하는 방법은 간단하다.
YML 설정을 통해 실행 순서를 변경할 수 있다.
resilience4j:
retry:
retry-aspect-order: 2
circuitbreaker:
circuit-breaker-aspect-order: 1
value가 높을수록 더 높은 우선순위를 나타낸다. 이에 대한 설명은 reslience4j 공식 문서에 나와있다.
https://resilience4j.readme.io/docs/getting-started-3#aspect-order
이후 테스트 코드는 성공하였고, 초기에 원하는대로 Retry가 Circuit Breaker보다 우선적으로 적용되도록 할 수 있었다.
마무리
이번에 처음으로 Retry와 Circuit Breaker를 한 기능에 동시에 사용하면서 위와 같은 문제 상황을 경험했다.
지나고 보면 "당연히 기능을 적용하기 전에 고려해야하는 것"이라고 느낄 수 있지만, 당시 상황에서는 무심코 놓치게 되었다.
라이브러리를 통해 추상화된 기능을 편리하게 사용할 수 있지만, 이처럼 여러 기능이 적용되고 원하는 우선순위가 있다면, 테스트를 통해 이를 확인해보는 것은 필수이다.