서비스의 상품 목록 조회를 개선해야한다는 미션이 주어졌다고 가정해보자.
우리는 이때 무엇을 시도할 수 있을까?
1️⃣ K6 성능 테스트
우선 지금 현재 상황이 어느정도인지 체크할 필요가 있다고 느꼈다.
현 서비스가 어느정도의 요청까지 버틸 수 있는지 알아야, 개선하더라도 얼만큼 개선된 것인지 파악할 수 있기 때문이다. 또한, 이 포인트를 알고 있어야 추후 서비스가 성장했을 때, 개선이 필요한 시점을 쉽게 잡을 수 있지 않을까 생각한다.
현재 상품 목록 조회는 페이지 처리가 포함되어 있고, 상품 목록 조회 기능은 브랜드 ID 필터링과 정렬 조건(최신순, 가격 낮은 순, 좋아요 많은 순)만 있다고 가정해보자.
테스트 환경은 다음과 같다.
- 상품 약 50만 개
- 브랜드 약 10만 개
- 인덱스 및 캐시 적용이 거의 없는 상황
상품 목록 조회 시 나가는 쿼리는 다음과 같다.
SELECT p.id, p.ref_brand_id, b.name, p.name, p.price, p.status, p.like_count from product as p
JOIN product_count AS pc ON p.id = pc.ref_product_id
JOIN brand AS b ON p.ref_brand_id = b.id
ORDER BY p.created_at DESC -- 또는 p.price ASC, pc.like_count DESC
LIMIT ?, ?;
SELECT COUNT(p.id) from product AS p
JOIN product_count AS pc on p.id = pc.ref_product_id
JOIN brand AS b ON p.ref_brand_id = b.id
SELECT m.id, m.birth_date, m.created_at, m.deleted_at, m.email, m.gender, m.login_id, m.updated_at from member AS m
WHERE m.id=?
SELECT pl.id, pl.created_at, pl.deleted_at, pl.ref_product_id, pl.updated_at, pl.ref_user_id FROM product_like AS pl
WHERE pl.ref_user_id = ? and pl.ref_product_id in (?,?,?,?,?,?,?,?,?,?)
위 상황에서 K6 테스트를 수행했다. 이번 개선 과정에서 사용한 K6 테스트 시나리오는 대략 다음과 같다.
- 초기 요청 (20초 동안 유지)
- 점진적 증가 (1m 동안 증가)
- 피크 유지 (1분동안 유지)
- 요청 감소 (20초 동안 유지 후 종료)
첫 테스트는 1 RPS → 5 RPS → 5 RPS → 1 RPS 로 수행하였다.
1 RPS → 5 RPS → 5 RPS → 1 RPS
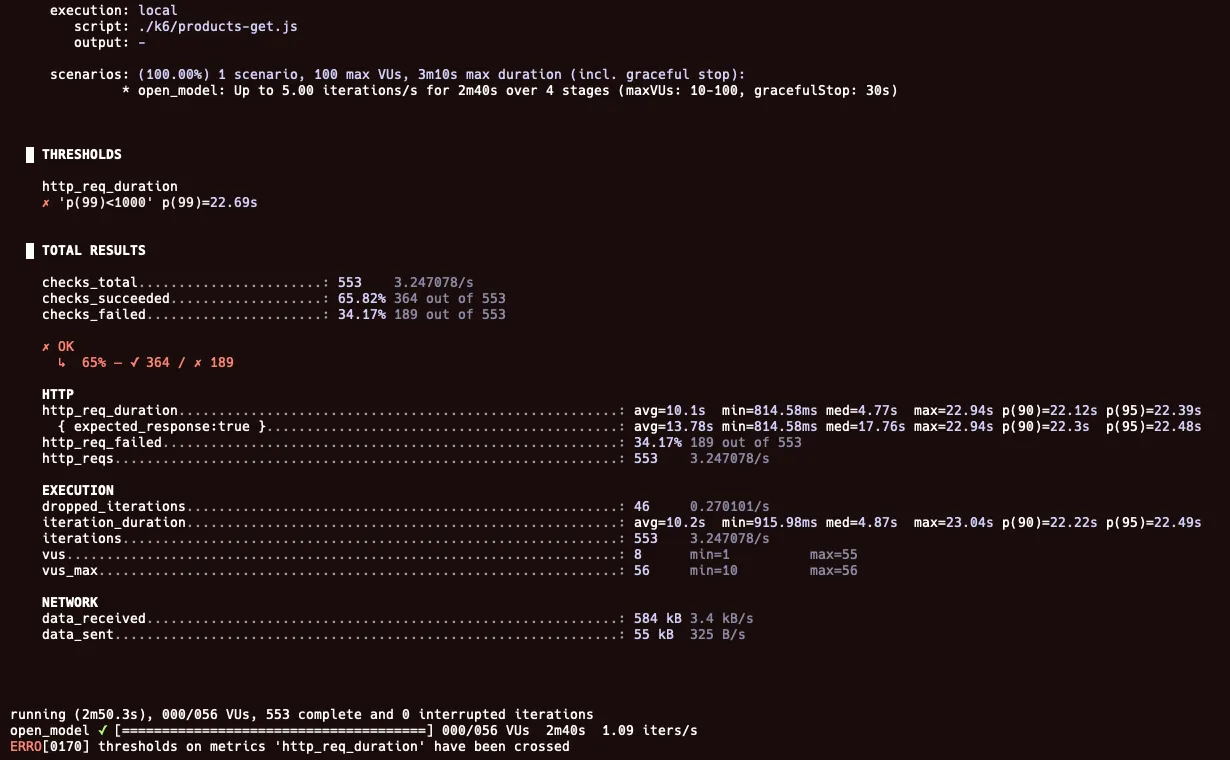
결과를 보면, 최소 814ms가 소요되는 것을 확인할 수 있다. 실패율도 34.17%로 상당히 높았고, 로그를 확인해보니 커넥션을 획득하지 못해 타임아웃이 발생했다.
이처럼 50만 개의 상품에 대한 목록을 조회했을 때, 소요 시간이 상당히 커서 5 RPS의 요청을 버티지 못했다.
이를 어떻게 개선할 수 있을까?
위의 4가지 쿼리를 개선해보자.
2️⃣ 쿼리 개선 - 인덱스
상품 조회 쿼리
페이지 내 상품 조회 쿼리는 다음과 같다.
SELECT p.id, p.ref_brand_id, b.name, p.name, p.price, p.status, pc.like_count from product as p
JOIN product_count AS pc ON p.id = pc.ref_product_id
JOIN brand AS b ON p.ref_brand_id = b.id
ORDER BY p.created_at DESC
LIMIT 100, 10; // 10번 페이지 가정현재 상황에서 위 쿼리의 실행계획을 확인해보자.

실행계획을 좀 더 우리말로 풀어보면, 다음과 같다.
모든 상품 정보를 가져오고, 그 정보들 중에서 최신순으로 정렬한다. 그 다음 100번째 ~ 110번째를 가져온다.
결국 몇 페이지에 상관없이 모든 상품을 풀스캔하고 있다. 그리고 filesort를 수행하고 있다. 이는 어떤게 최신순 100번째 ~ 110번째인지 모르기 때문에, 전체를 훑어본 후 정렬을 수행하기 때문이다.
filesort란 조회된 레코드를 정렬용 메모리 버퍼에 복사해 퀵 소트 또는 힙 소트 알고리즘을 이용해 정렬을 수행한다.
그렇다면, 우리가 페이지에 해당하는 상품들에 효율적으로 접근하기 위해서는 어떻게 해야할까?
이에 해당하는 인덱스를 설정할 수 있다.
풀스캔을 해결하기 위해, (created_at)에 해당하는 인덱스를 추가하였다. 이후 실행계획을 확인해보자.

풀스캔에 비해 매우 효과적으로 스캔하는 row가 줄었다.
이는 인덱스를 통해 가장 최신순부터 차례로 탐색하다가, 페이지에 해당하는 만큼 찾으면 더 이상 찾을 필요가 없기 때문이다.
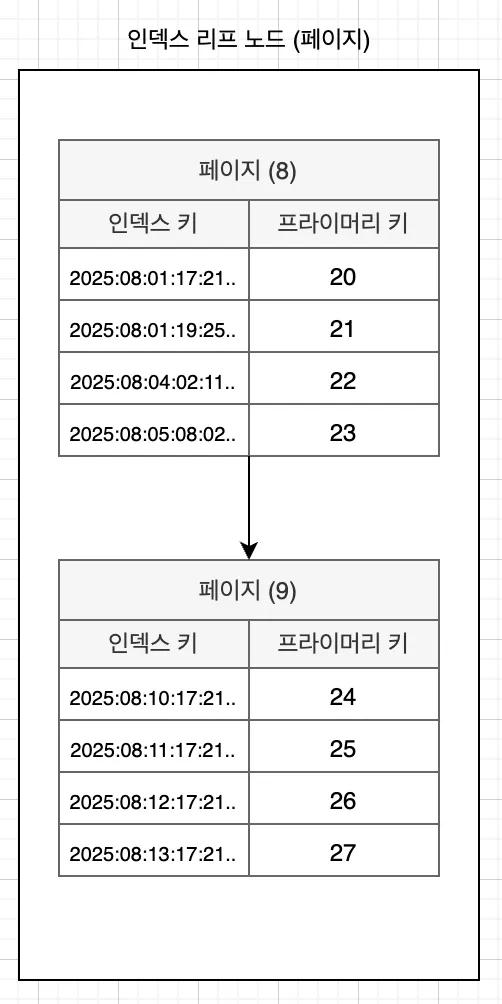
위처럼 정렬된 인덱스 리프 노드를 탐색하고, 이후 PK 인덱스를 통해 실제 레코드에 접근한다.
MySQL의 InnoDB에서 인덱스의 리프 노드는 레코드의 주소가 아닌 PK를 가지고 있다. 이는 InnoDB의 PK 인덱스가 클러스터링 인덱스이기 때문이다. 관련 내용은 <Real MySQL 8.0>의 인덱스 파트를 참고하면 자세히 나와있다.
위 쿼리에서 브랜드 ID 필터링 조건이 추가된다면 어떨까?

product 테이블을 (created_at) 인덱스 순서로 스캔하면서, 그 중 브랜드 조건을 통해 거른다. 즉, created_at 인덱스를 먼저 스캔하면서 브랜드 조건을 필터링하고, 마지막에 product_count 을 붙인다.
using where 는 MySQL 엔진 레이어에서 별도의 가공을 해서 필터링 작업을 처리한 경우를 말한다.
(브랜드 필터링 + 최신순)에 맞게 인덱스를 걸고, 실행계획을 다시 확인해보자.

복합 인덱스를 사용해, 브랜드에 해당하는 제품에 바로 접근할 수 있다. 브랜드 하나 당 상품 50개를 가지도록 세팅해서, rows가 그대로 50개가 나오는 것을 확인할 수 있다.
추가 고민: 조회 필터링이 다양하다면 어떻게 해야할까?
현재 상품 목록 조회에서 필터링은 다양하지 않다. 그래서 인덱스에 큰 고민없이 도입할 수 있었다. 하지만 상품 목록 조회 조건이 다양한 조합으로 이루어질 수 있다면 어떻게 해야할까?그때는 가장 모수를 줄일 수 있는 방법을 고려해야할 것이다. 모든 필터링마다 인덱스를 걸어놓는 것은 쓰기 부하가 너무 커질 수 있다.
카운트 쿼리
페이지네이션에 사용되는 카운트 쿼리는 다음과 같다.
explain SELECT COUNT(p.id) from product AS p
JOIN product_count AS pc on p.id = pc.ref_product_id
JOIN brand AS b ON p.ref_brand_id = b.id
카운트 쿼리의 실행계획을 살펴보자.

카운트 쿼리는 인덱스를 사용한다 하더라도, 전체 상품 목록 조회의 경우, 풀스캔이 불가피하다. 그래서 카운트 쿼리는 비용이 상당히 높은편이다.
실제로 구글에서 ‘넷플릭스’를 검색해보면 아래와 같이 나온다.
생략 결과를 포함하여 다시 조회할 수는 있지만, 18 페이지 정도까지만 가능하다. 점점 관련성도 옅어지겠지만, 페이지 수를 실제 데이터 개수만큼 제공한다면 카운트 쿼리로 인한 성능적인 문제도 있을 것 같다.

상품 좋아요
SELECT pl.id, pl.created_at, pl.deleted_at, pl.ref_product_id, pl.updated_at, pl.ref_user_id
FROM product_like AS pl
WHERE pl.ref_user_id = 10 and pl.ref_product_id in (20,21,22,23,24,25,26,27,28,29)
조회한 상품 목록에 대해 사용자의 좋아요 여부를 조회하기 위한 쿼리이다. 이 쿼리에 대한 실행계획을 살펴보자.

기존에 상품 좋아요의 경우, (유저-상품 좋아요)는 1개만 가능하므로 유니크 인덱스를 걸려있었다. 그래서 위 쿼리에 적절한 인덱스가 이미 걸려있었다.
⏸️ 중간 결과 테스트 - 인덱스
인덱스를 설정한 후 성능이 어느정도로 개선되었는지 확인해보자. 다시 K6를 통해 테스트를 해보았다. 테스트 시나리오는 똑같이 1 RPS -> 5RPS -> 5 RPS -> 1 RPS 로 구성하였다.
1 RPS → 5 RPS → 5 RPS → 1 RPS
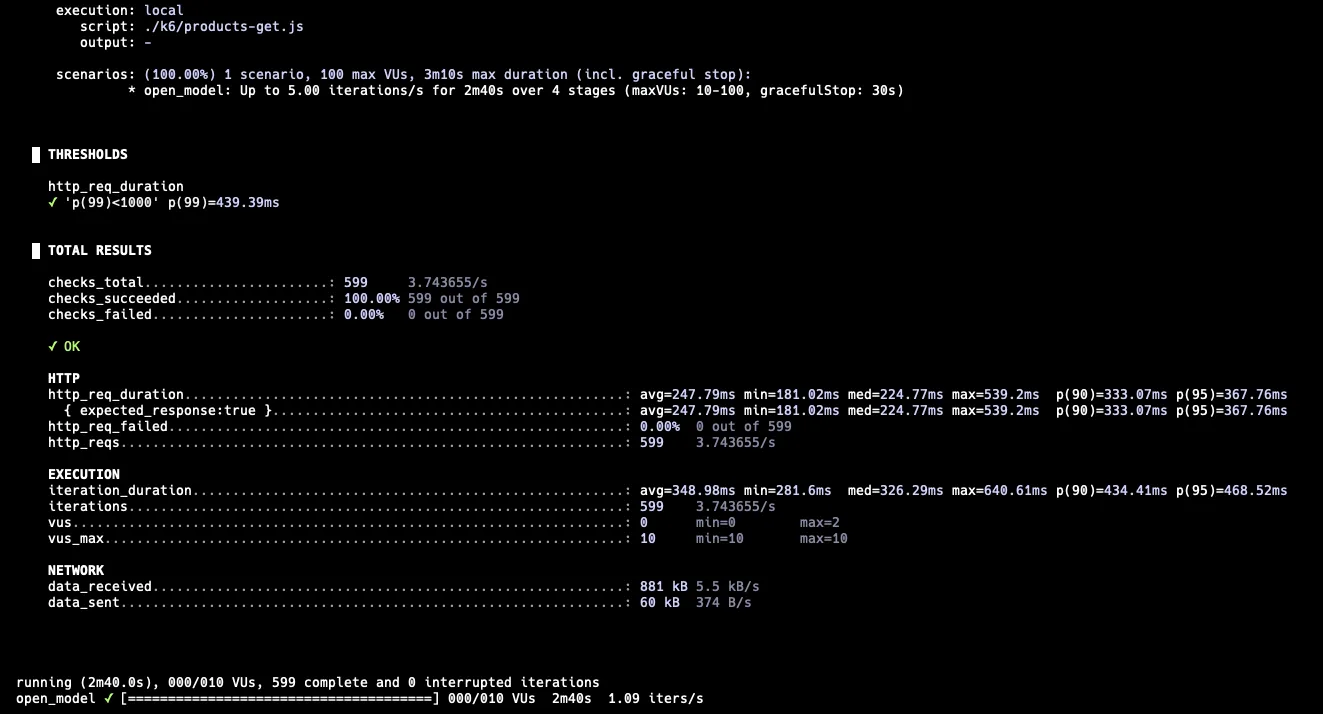
기존에 비해 성능이 개선되었다.
최소 소요 시간도 약 814ms에서 181ms로 감소하였고, 5 RPS는 충분히 버틸 수 있다. RPS를 더 테스트해보자.
5 RPS → 10 RPS → 10 RPS → 5 RPS
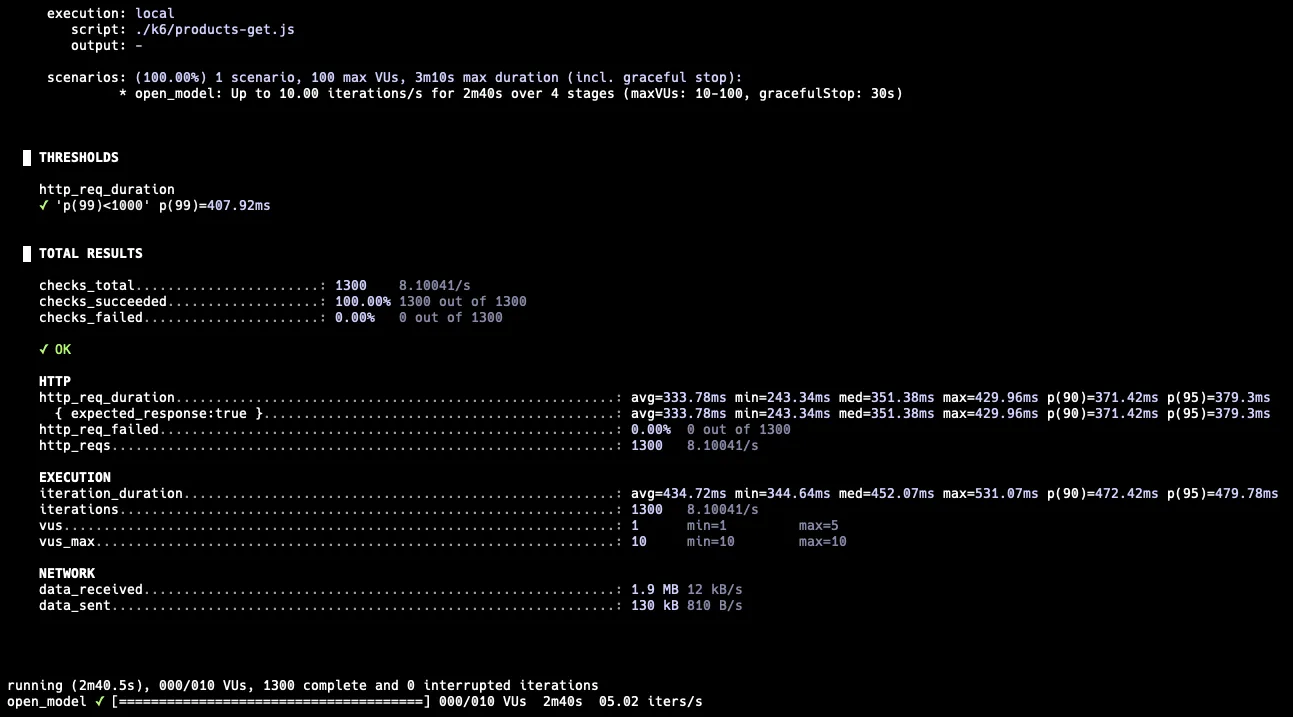
5 RPS → 15 RPS → 15 RPS → 5 RPS
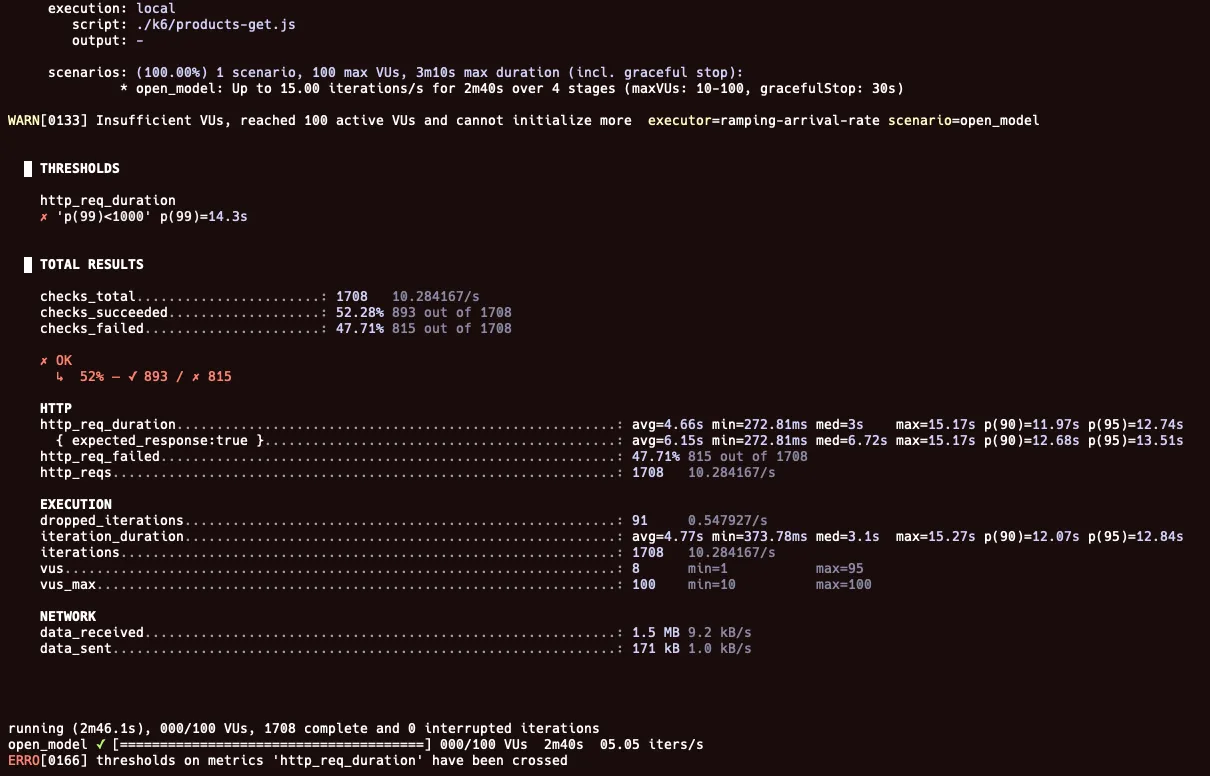
최대 15 RPS까지 올리니 실패했다. 이때 실패율이 거의 50%까지 된다.
이를 통해 인덱스 작업한 이후, 약 10 RPS까지 가능한 것으로 확인되었다.
여기서 어떻게 더 개선할 수 있을까?
3️⃣ 캐시 적용
위 작업에서 카운트 쿼리가 가장 큰 병목이다. 카운트 쿼리에 대한 소요 시간을 어떻게 줄일 수 있을까?
매 번 정확한 상품 개수를 가져와야 한다면, 직접 DB에 조회해야 한다. 하지만 매 번 100% 정합성이 지켜지지 않아도 된다면, 스냅샷을 찍고 이를 제공하는 방안이 있다.
캐시를 적용해야하는 기준
그렇다면 전체 상품 개수가 매 번 항상 정합성이 지켜져야 하는지 생각해보자.
상품 목록 조회 시, 대부분 사용자는 앞 부분 페이지를 조회하게 된다. 맨 뒤 페이지까지 조회하여 마지막 데이터를 가져와야 하는 경우는 비교적 흔치 않다.
또한, 상품이 추가되어 상품 수가 달라지는 것보다, 상품 목록을 조회하는 비율이 훨씬 클 것이다. 사용자가 상품 목록을 조회할 때마다 캐시된 데이터가 사용되므로, 히트율 또한 상당히 높은 편이다.
이러한 이유로 전체 상품 수에 캐시를 적용해도 될 것이라 판단하였다.
캐시 관리
캐시를 관리하는 방법은 여러 가지가 있다. 읽기/쓰기에도 Look Aside, Write Through, Write Back 등 다양하다.
이번 상품 목록 조회 에서는 스케쥴러를 통해 상품 수를 갱신하는 방법을 선택했다.
이러한 선택의 이유는 상품 목록 조회는 다른 기능보다도 정말 빈번하게 요청되고, 히트율 또한 상당히 높다고 판단했다. 그래서 캐시가 잠시 비는 시간에 발생할 수 있는 캐시 스탬피드 문제 자체를 방지하고자 하였다.
그래서 캐시의 TTL은 6분, 캐시 갱신은 5분 주기로 실행하였다.
상품 목록 조회는 다음과 같은 흐름으로 진행된다.
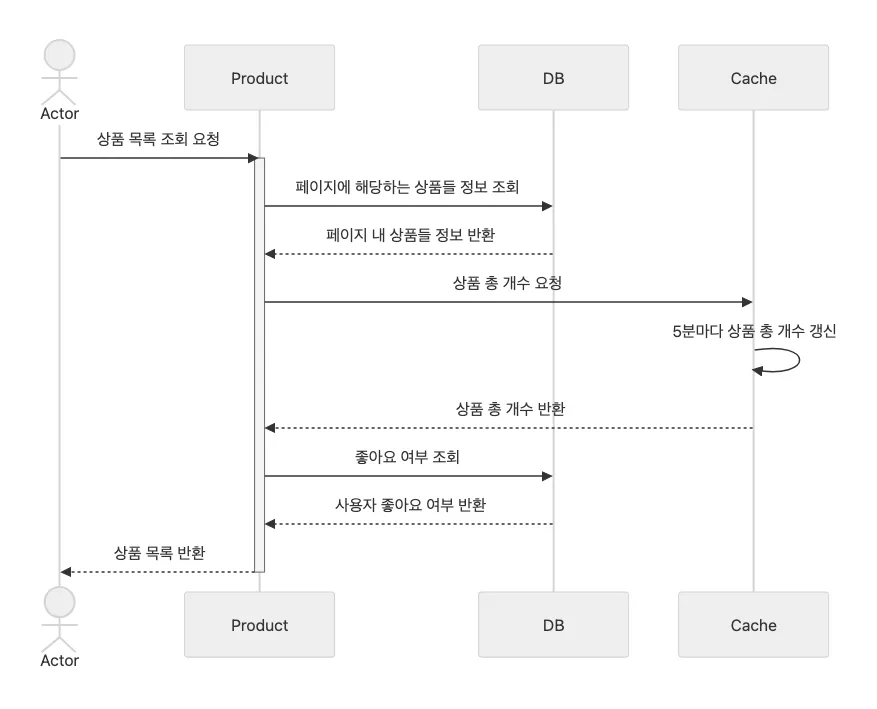
4️⃣ 최종 결과 테스트 및 비교 - 인덱스 + 캐시
이제 인덱스와 캐시를 적용한 결과를 테스트해보자.
5 RPS → 20 RPS → 20 RPS → 5RPS
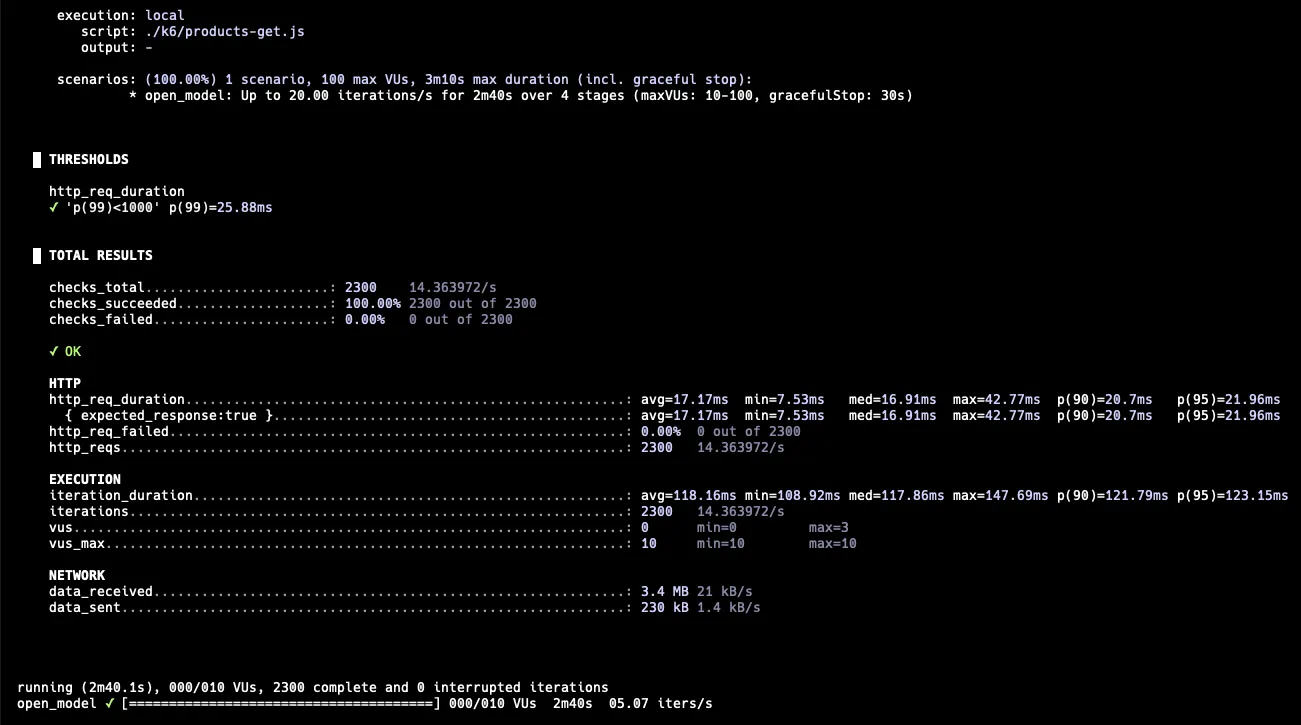
API 응답 최소 시간도 상당히 많이 줄었다. 인덱스를 적용하기 전, 약 250ms 에서 약 8ms로 대폭 감소했다. p99도 25.88ms로 20 RPS에서 충분한 성능이다.
이를 통해, 상품 목록 조회에서 카운트 쿼리가 큰 병목이었음을 알 수 있다.
RPS를 더 올려서 테스트해보자.
최대 300 RPS
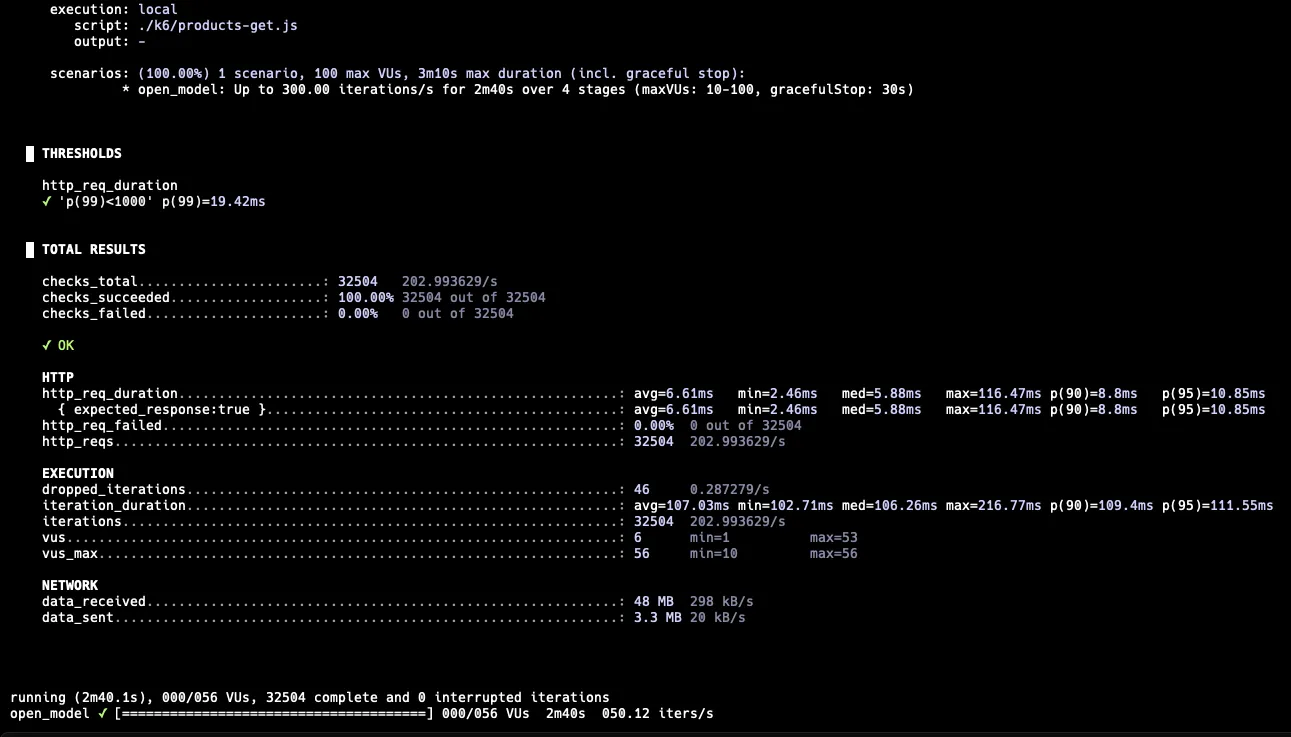
300 RPS에서도 실패하는 케이스는 없었고, p99는 19.42ms로 나왔다. 하지만 이전 테스트에 비해 VU가 점차 쌓이기 시작하면서 56개까지 생성되었다.
이제 지금까지의 모든 결과를 한번에 비교해보자.

인덱스를 통해 상품을 가져오는 과정에서 효율적으로 조회할 수 있었다.
하지만 카운트 쿼리같은 경우, 풀스캔이 불가피하여 개선하기가 어렵다. 이는 캐시를 적용하여 매 번 카운트 쿼리를 날릴 필요가 없도록 하였고, 이를 통해 조회 성능을 대폭 향상시킬 수 있었다.
5️⃣ 마무리
이번 과제에서 인덱스와 캐시를 도입하여 조회 성능을 개선해보았다.
인덱스와 캐시를 적용하는 것 자체는 어렵지 않았다. 코드 작성량이 많거나, 설정하는 과정에서 큰 어려움을 겪지 않았다.
하지만 그 과정에서 어떠한 판단을 내리는지가 중요하다고 느꼈다.
어떠한 전략을 사용하고, 어떻게 관리할 것인지는 비즈니스에 따라 유동적으로 선택할 수 있어야 한다.
스스로 어떠한 정답을 내려놓고 이를 매 상황에 적용하기보다, ‘인덱스가 효율적으로 잘 타는지’, ‘캐시의 지속시간이 적절한지’, ‘캐시 히트율이 높을지’와 같은 다양한 고민을 자연스럽게 하게 되었다.
인덱스를 쿼리에 맞게 효율적으로 설정하고, 상황에 맞는 적절한 캐시 전략을 비교하여 선택할 수 있도록 하자.