보틀러에서 알림이 필요한 경우, 알림이 저장되고 푸시 알림이 전송됩니다. 이때 푸시 알림이 전송되기를 기다리기보다는 비동기적으로 푸시 알림을 전송하는 것이 효율적이라 판단하였습니다.
📌 비동기 처리란?
비동기 처리는 작업의 결과를 기다리지 않고 다른 작업을 진행하는 방식입니다.
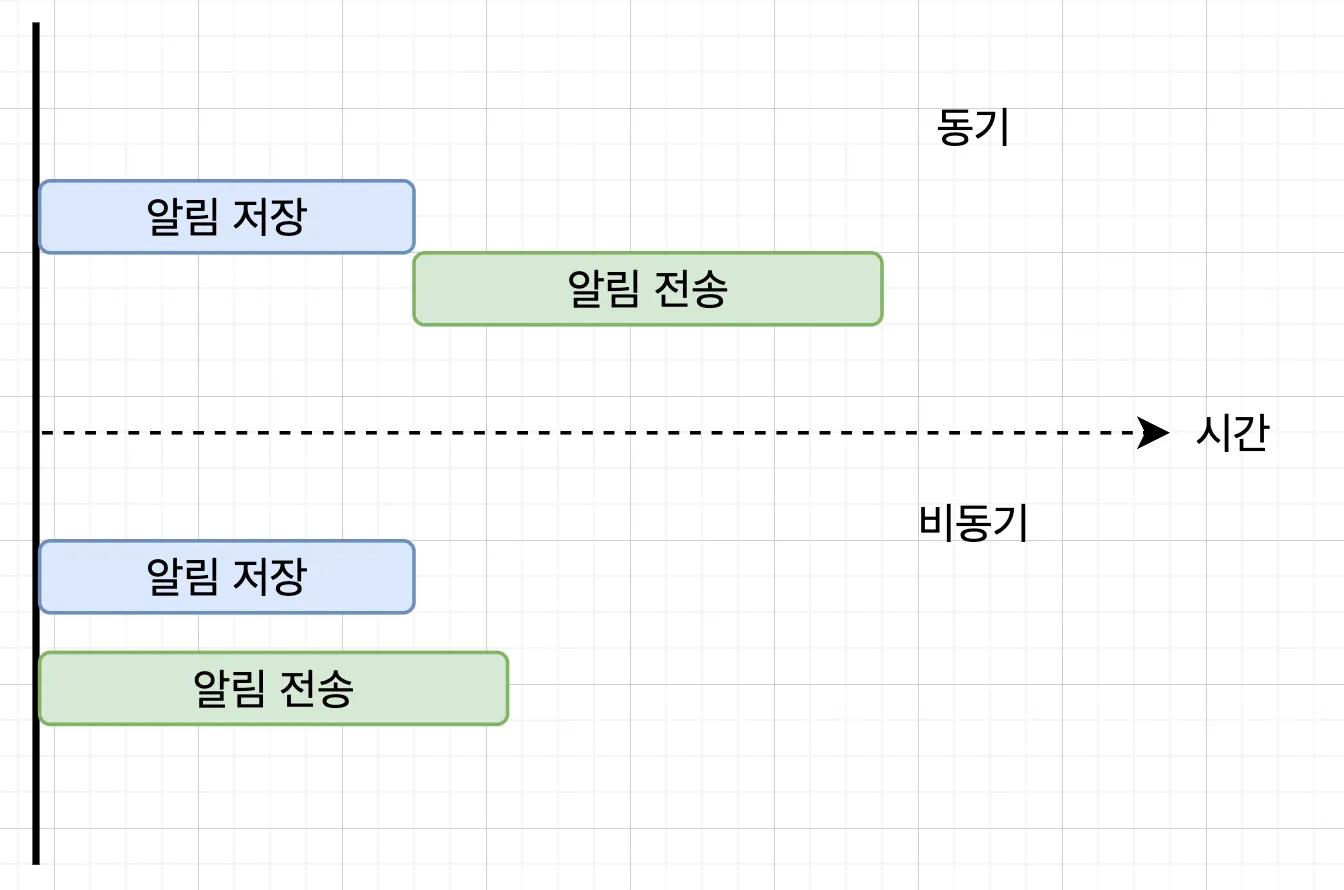
푸시 알림 전송의 경우, 전송 결과를 통한 추가 작업이 존재하지 않고 FCM을 이용하기 때문에 비동기 작업으로 진행해도 괜찮다 판단하였습니다.
그렇다면 스프링에서 비동기 처리는 어떻게 할 수 있을까요?
📌 스프링에서의 비동기 처리
스레드 생성 이용하기
직접 스레드를 생성하여 실행시키는 방법이 있습니다.
private void pushMessage(NotificationType type, Subscriptions subscriptions) {
PushMessages pushMessages = subscriptions.makeMessages(type);
new Thread(() -> pushNotificationProvider.pushAll(pushMessages)).start();
}
직접 스레드를 생성하여 비동기 처리를 할 수 있지만, 비즈니스 로직에 비동기 관련 로직이 섞여있게 됩니다. 또한, 스레드풀에서 스레드를 가져오는 것이 아니라 새롭게 생성하기 때문에 문제가 발생할 가능성이 있습니다.
@Async를 이용한 비동기 처리
@Async 어노테이션을 활용한 비동기 처리는 간단합니다.
- @EnableAsync 어노테이션을 통해 비동기 처리 기능을 활성화시켜 @Async가 붙은 메서드를 비동기적으로 실행할 수 있게 한다.
- @Async 어노테이션을 메서드에 등록한다.
위 순서대로 @Async 어노테이션을 비동기적으로 처리하려는 메서드에 적용하였습니다.
@Slf4j
@Component
@RequiredArgsConstructor
public class FirebasePushProvider implements PushNotificationProvider {
private final FirebaseMessageMapper messageMapper;
@Override
@Async
public void pushAll(PushMessages pushMessages) {
List<Message> firebaseMessages = messageMapper.mapToFirebaseMessages(pushMessages);
try {
FirebaseMessaging.getInstance().sendEach(firebaseMessages);
} catch (FirebaseMessagingException e) {
log.error("알림 푸시 실패 : {}", e.getMessage());
}
}
}
📌 @Async는 어떻게 비동기적으로 처리되는걸까?
@Async는 트랜잭션과 유사하게 스프링 AOP에 의해 프록시 패턴으로 동작합니다.
- @Async 어노테이션이 붙은 메서드가 호출되면, 스프링은 비동기 실행을 처리하기 위해 프록시 객체에 접근한다.
- 해당 메서드는 TaskExecutor에 의해 스레드풀에 작업으로 등록한다.
- 해당 메서드는 별도 스레드에서 작업이 진행된다.
프록시 패턴으로 진행되기 때문에 트랜잭션 프록시와 유사하게 두 가지 조건이 존재합니다.
- public 메서드에서만 적용 가능
- 같은 클래스의 메서드를 호출할 수 없다.
위 내용은 @EnableAsync의 AdviceMode가 PROXY인 경우에 해당됩니다.
📌 @EnableAsync 설정
@EnableAsync 어노테이션은 어플리케이션 클래스에 붙여 설정할 수 있습니다.
별도의 TaskExecutor를 설정하지 않으면 SimpleAsyncTaskExecutor가 실행되지만, @SpringBootApplication 어노테이션 내에 ThreadPoolTaskExecutor를 등록시키는 과정이 포함되어 있습니다.
- SimpleAsyncTaskExecutor
- 스레드풀을 사용하지 않고, 새로운 스레드를 생성하여 작업 수행
- ThreadPoolTaskExecutor
- 스레드풀 사용하여 재사용 가능한 스레드 유지
- 최대 스레드 수 설정 가능
그렇다면 SimpleAsyncTaskExecutor를 사용하지 않고 다른 Executor를 사용하는 방법은 무엇이 있을까요?
1. Application 클래스에 적용
@SpringBootApplication을 타고 들어가면 @EnableAutoConfiguration이 존재하는데, 이 내부에 TaskExecutionAutoConfiguration이 존재합니다. 이때 TaskExecutor로 ThreadPoolTaskExecutor를 등합니다.
따라서 저는 어플리케이션 클래스에 @EnableAsync를 등록한 후, application.yml 파일에 스레드풀 설정을 작성하였습니다.
@SpringBootApplication
@EnableAsync
public class BottlerApplication {
public static void main(String[] args) {
SpringApplication.run(BottlerApplication.class, args);
}
}
spring:
task:
execution:
pool:
core-size: 4 # 최소 스레드 수 (HikariCP와 동일)
max-size: 4 # 최대 스레드 수 (HikariCP와 동일)
queue-capacity: 50 # 대기 큐 크기
shutdown:
await-termination: true # 종료 시 남은 작업을 마무리
await-termination-period: 30s # 종료 대기 시간
2. AsyncConfigurer 인터페이스 활용
AsyncConfigurer 인터페이스를 구현하여 별도의 TaskExecutor를 설정할 수 있습니다.
@EnableAsync
@Configuration
public class AsyncConfig implements AsyncConfigurer {
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(4);
executor.setQueueCapacity(50);
executor.setKeepAliveSeconds(30);
executor.initialize();
return executor;
}
}
3. @Bean 활용
Executor를 Bean으로 등록하여 활용할 수 있습니다. 여러 개의 Bean으로 등록하여 활용할 수 있는데 프로필별로 다른 스레드풀을 쓰고자할 때 유용합니다.
@EnableAsync
@Configuration
public class AsyncConfig {
@Bean
public Executor asyncExecutor1() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(4);
executor.setQueueCapacity(50);
executor.setKeepAliveSeconds(30);
executor.initialize();
return executor;
}
@Bean
public Executor asyncExecutor2() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(8);
executor.setMaxPoolSize(8);
executor.setQueueCapacity(100);
executor.setKeepAliveSeconds(60);
executor.initialize();
return executor;
}
}
📌 ThreadPoolTaskExecutor가 처리하는 방식
- 스레드풀에 작업이 등록되면, corePoolSize 만큼의 스레드가 존재하는지 확인
- 스레드에 작업 할당
- corePoolSize보다 적다면, 스레드를 생성하여 작업 할당
- corePoolSize보다 크다면, 대기 상태 스레드에게 작업 할당
- 스레드풀에 존재하는 모든 스레드가 작업 중이라면 Queue에 작업을 넣고 대기
- Queue가 가득 찬 경우, 현재 스레드풀의 스레드 개수가 maxPoolSize를 넘지 않으면 새로운 스레드를 생성하여 작업 할당
- Queue가 가득 차고 maxPoolSize에 도달한 상태에서 새로운 요청이 들어오면, TaskRejectedException 발생
- 작업 중인 스레드가 작업을 마치면, Queue에 대기 중인 작업이 있는지 확인
- 대기 중인 작업이 있다면, 해당 작업 수행
- 대기 중인 작업이 없다면, 대기 상태로 돌아간다. 스레드풀의 스레드 개수가 corePoolSize보다 크면 keepAliveTime이 지나고 해당 스레드는 스레드풀에서 제거된다.
예외 처리
예외가 발생했을 때 RejectedExecutionHandler를 통해 예외 전략을 설정할 수 있습니다. RejectedExecutionHandler의 기본 전략은 AbortPolicy입니다.
- AbortPolicy : TaskRejectedException을 발생시키며 종료
- CallerRunsPolicy : 스레드풀을 호출한 스레드에서 처리
- DiscardPolicy : 해당 요청 무시
- DiscardOldestPolicy : 큐에 있는 가장 오래된 요청을 삭제하고 새로운 요청을 받음.
@EnableAsync
@Configuration
public class AsyncConfig implements AsyncConfigurer {
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 예외 처리 방법 1
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardPolicy());
// 예외 처리 방법 2 (커스텀)
executor.setRejectedExecutionHandler((r, exec) -> {
throw new RuntimeException("요청 처리 불가.");
});
executor.initialize();
return executor;
}
}
저는 따로 설정하지 않고 AbortPolicy를 유지한 채 진행하였습니다.
📌 처리 결과
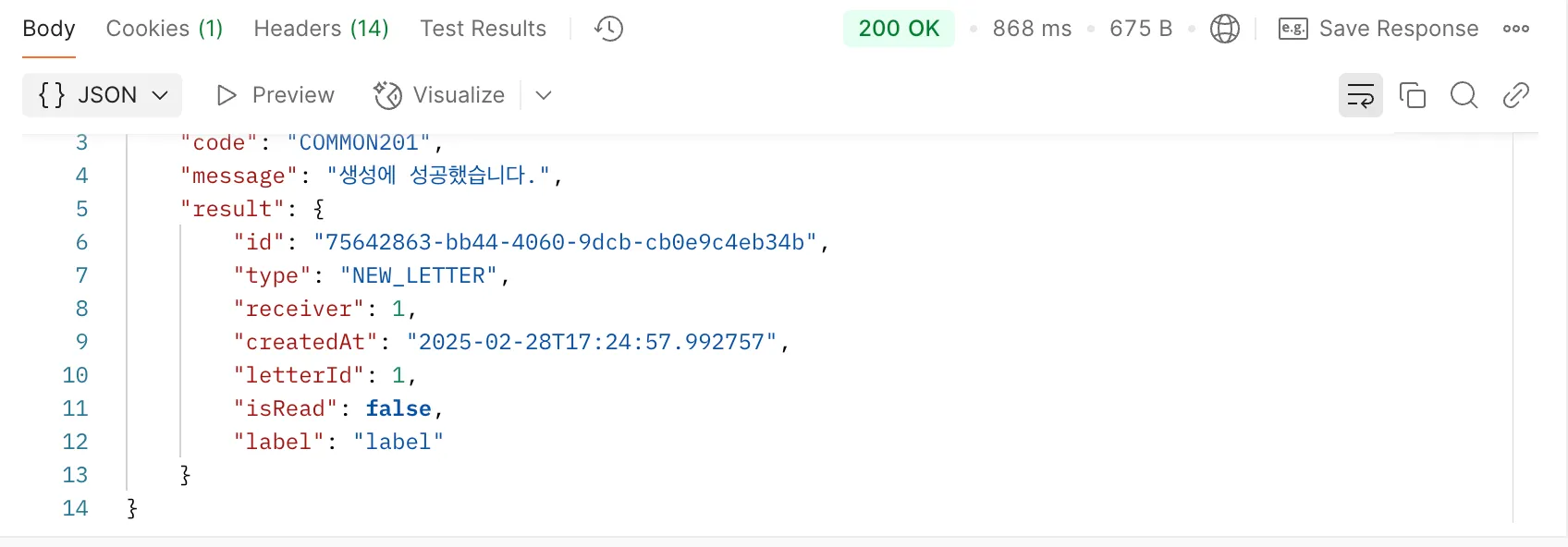
비동기 처리를 통해 알림 전송 API 응답 시간이 단축되었습니다.
- 기존 소요 시간
- 비동기 처리 후 소요 시간
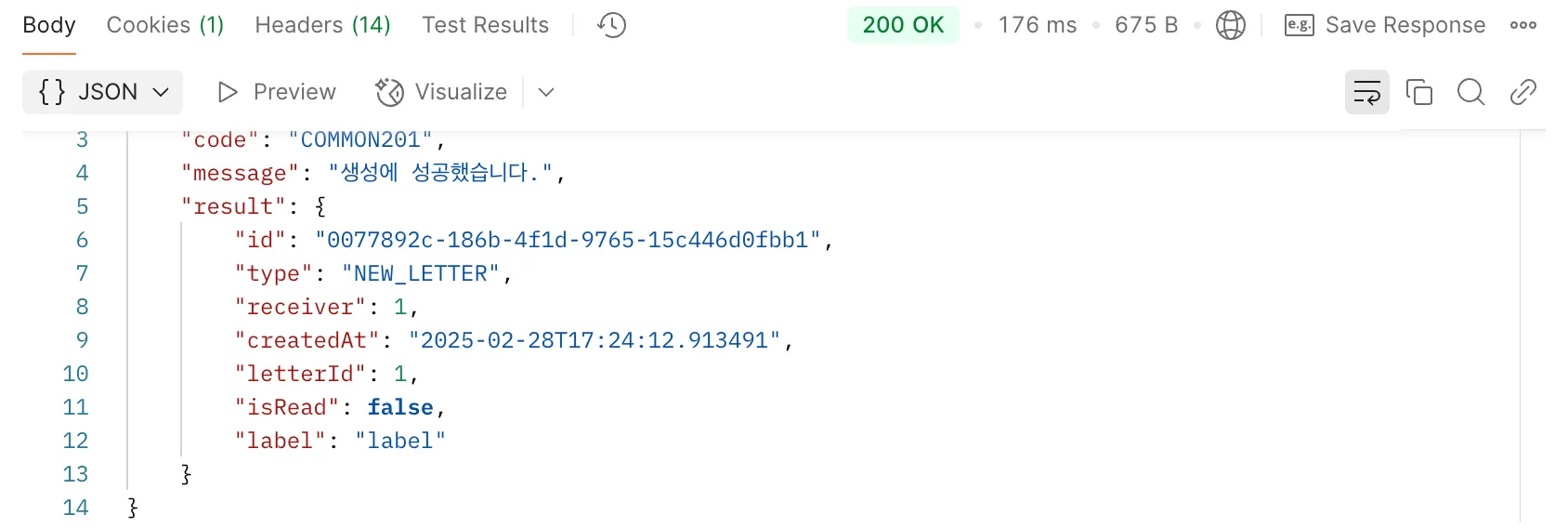
비동기 처리를 통해 약 0.6s 정도를 단축할 수 있었습니다. 참고로 비동기 처리 진행 시, 기존에 가지고 있던 트랜잭션을 그대로 들고 가지 않습니다. 트랜잭션은 하나의 스레드 내에서 유지되기 때문에, 다른 스레드에서의 작업은 부모 트랜잭션이 유지되지 않습니다. 따라서 해당 작업이 하나의 트랜잭션으로 진행되어야 하는지에 대한 확인도 꼭 이루어져야 합니다.
참고
'스프링' 카테고리의 다른 글
| @Modifying의 동작 알아보기 (0) | 2025.01.23 |
|---|---|
| [JPA] 연관관계의 주인이란? (0) | 2025.01.13 |
| Mybatis vs JPA (0) | 2025.01.08 |
| SELECT 작업에 트랜잭션은 필요할까? (0) | 2025.01.08 |
| 스프링 트랜잭션 (0) | 2025.01.07 |